

GMKtec EVO-X2 vs. NVIDIA DGX SPARK: Local AI Performance Benchmark
- Nagy Róbert
- 1 day ago
- 1 min read

GMKtec EVO-X2 vs. NVIDIA DGX SPARK: Local AI Performance Benchmark
As local large language models (LLMs) become increasingly vital for content creation, coding, and enterprise intelligence, Mini PCs are stepping into a new era of AI computing.GMKtec’s EVO-X2, powered by the AMD Ryzen™ AI platform, has been benchmarked against NVIDIA DGX SPARK to test real-world local AI capabilities.
The evaluation covers four popular open-source models, Llama 3.3 70B, Qwen3 Coder, GPT-OSS 20B, and Qwen3 0.6B, comparing generation speed (tokens/sec) and first token response time (s) across both devices.
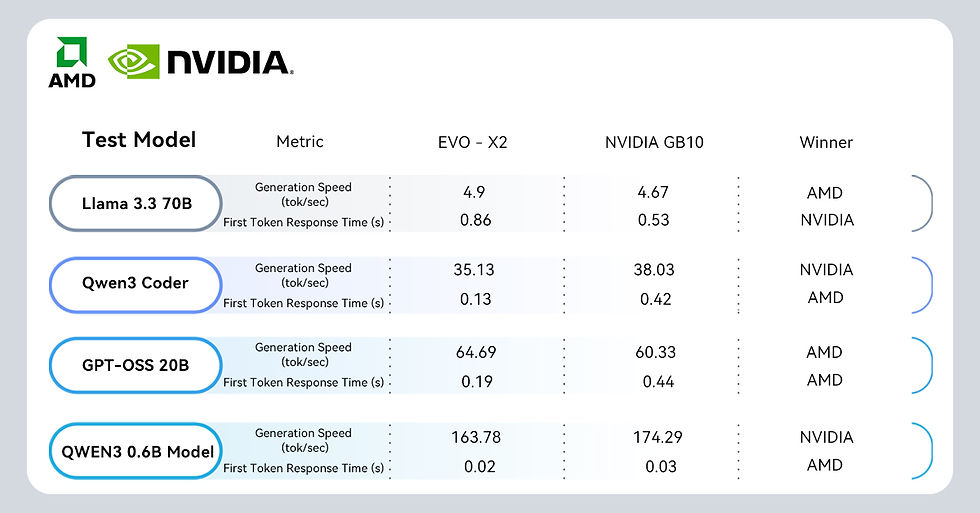
⚙️ Performance Insights
Across the tests, GMKtec EVO-X2 demonstrates remarkable efficiency in handling local AI workloads.
For medium to large models (20B–70B), the EVO-X2 consistently delivers faster generation speeds, particularly excelling in the GPT-OSS 20B and Llama 3.3 70B benchmarks.
In first-token latency, EVO-X2 achieves significantly lower response times in multiple models, showcasing AMD’s optimized memory bandwidth and local AI acceleration architecture.
🚀 Why EVO-X2 Excels in Local AI
AMD Ryzen™ AI EngineHarnesses dedicated AI acceleration for multi-threaded, low-latency inference performance.
Open Ecosystem CompatibilityFully supports major open-source AI models (Llama, Qwen, Mistral) and frameworks (Ollama, LM Studio, vLLM).
Superior Performance-to-Power RatioDelivers workstation-level AI capability within a compact Mini PC form factor, with exceptional energy efficiency.
Local AI Workflow ReadyDeploy and run models directly on-device — no cloud dependency, enhanced data privacy, and instant responsiveness.
🧠 Conclusion
The results prove that GMKtec EVO-X2, powered by AMD, competes head-to-head with NVIDIA’s DGX SPARK — even surpassing it in several key performance areas, especially in real-world latency and response efficiency.
Compact in size, powerful in intelligence, EVO-X2 redefines what’s possible for local AI computing.



Comments